Spring Boot is one of the most popular frameworks for building Java based applications, making it a must-know for developers preparing for interviews. Whether you’re a fresher or an experienced professional, understanding key Spring Boot concepts like dependency injection, microservices, and REST APIs is crucial. In this tutorial, we’ve compiled the most commonly asked Spring Boot interview questions with detailed answers to help you confidently crack your next interview.
Spring Boot Interview Questions with Detailed Answers
Basics of Spring Boot
1. What is Spring Boot and why is it used?
Answer: Spring Boot simplifies Java application development by providing auto-configuration, embedded servers, and production-ready features.
Example:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
- What are the main features and advantages of using Spring Boot for application development?
Auto-configuration in Spring Boot is one of its key features that simplifies application setup. In traditional Spring, when setting up a project, developers had to manually configure both their own classes and the Spring-provided classes, such as data sources, transaction managers, or web servers. This often involved a significant amount of boilerplate code.
With Spring Boot, it takes a more streamlined approach by automatically configuring Spring beans based on the dependencies available in the classpath. This means developers don’t need to write configuration for Spring-provided classes (like data sources, embedded web servers, or security) unless custom behavior is needed. Essentially, Spring Boot handles the configuration of Spring’s default beans for us.
For instance, if a developer includes a dependency like Spring Data JPA in their project, Spring Boot will automatically configure a DataSource and other related beans, such as EntityManagerFactory, without needing to manually define them in configuration files. The focus is now solely on configuring only the custom beans (i.e., the classes specific to the application), reducing boilerplate and letting developers concentrate on the application’s business logic instead of infrastructure concerns.
This approach significantly reduces the amount of configuration you have to do and allows you to focus more on the business logic of your application.
- Embedded Servers: Spring Boot comes with embedded servers like Tomcat, Jetty, or Undertow, so you don’t need to deploy WAR files or set up an external server.
- Spring Boot Actuator: It includes built-in production-ready features like health checks, metrics, application monitoring, and externalized configuration.
- Starter Dependencies: Spring Boot simplifies dependency management with a set of curated, versioned dependencies that work well together.
- Spring Boot CLI: A command-line interface for running and testing Spring Boot applications quickly, allowing you to write Groovy scripts and start applications with minimal setup.
- Spring Boot DevTools: Provides a set of tools to improve the development experience, such as automatic restarts, live reload, and enhanced logging, to speed up development cycles.
- What are Spring Boot starters?
Answer: Spring Boot Starters are pre-configured Maven dependencies that simplify adding specific features to your Spring Boot application. When you include a starter, you don’t need to manually add its transitive dependencies, as they are already included. Starters group together commonly used dependencies for features like web development, security, data access, etc., allowing for easy integration.
Example:
- spring-boot-starter-web for web apps.
- spring-boot-starter-security for security features.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
- Explain the @SpringBootApplication annotation.
Answer: The @SpringBootApplication annotation is a convenience annotation in Spring Boot that combines three essential annotations to simplify the setup of a Spring Boot application:
- @Configuration: Marks the class as a source of bean definitions for the application context. It is equivalent to using XML configuration in traditional Spring, but in a more concise and Java-based way.
- @EnableAutoConfiguration: Tells Spring Boot to automatically configure the application based on the dependencies present in the classpath. This reduces the need for manual configuration and setup, making it easier to create production-ready applications.
- @ComponentScan: Tells Spring to scan the package (and sub-packages) for components, configurations, and services. This allows Spring to discover and register beans, such as @Controller, @Service, @Repository, etc.
By using @SpringBootApplication, developers can avoid manually writing boilerplate configuration code, making the development process faster and more efficient. This annotation is typically used on the main class that starts the Spring Boot application.
- How to create a Spring Boot application?
Answer: While the most common approach is to create a Java class with the @SpringBootApplication annotation and use SpringApplication.run() to launch the application, there are different ways to create a Spring Boot application depending on the requirements. Below are the key methods:
- Using the @SpringBootApplication annotation: The simplest and most common method is to create a Java class with the @SpringBootApplication annotation. This annotation combines @Configuration, @EnableAutoConfiguration, and @ComponentScan to simplify the configuration and component scanning.
- Using Spring Initializr: You can also create a Spring Boot application using Spring Initializr (https://start.spring.io/), which provides a web-based interface for generating Spring Boot projects. You can select dependencies, project metadata, and generate a ready-to-use project in a few clicks.
- Using Spring Boot CLI: The Spring Boot CLI (Command-Line Interface) allows you to quickly create Spring Boot applications using Groovy scripts. You can write a Groovy script (e.g., app.groovy) and execute it using the Spring Boot CLI tool.
- Using Maven or Gradle: You can create a Spring Boot application by configuring a Maven or Gradle project with the necessary dependencies and settings. In Maven, you need the spring-boot-starter-parent as the parent and spring-boot-maven-plugin for packaging. Similarly, for Gradle, you’d configure the appropriate plugin and dependencies in build.gradle.
Spring Boot Configuration
- How to configure Spring Boot using application.properties?
Answer: You can set properties like database configurations, logging settings, server ports, etc.
Example:
server.port=8080
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
- What is the difference between application.properties and application.yml?
Answer: Both application.properties and application.yml are used for configuration in Spring Boot applications, but they differ primarily in format. application.properties uses a simple key-value pair format, where each property is defined on a separate line, making it ideal for flat and simple configurations. On the other hand, application.yml uses YAML format, which supports hierarchical structures and is considered more readable, especially for complex or nested configurations. YAML’s indentation-based structure makes it easier to organize related properties in a clean and visually clear manner. While both formats are supported in Spring Boot and can be used interchangeably, application.properties tends to be favored for simpler setups, whereas application.yml is preferred when dealing with more intricate configurations. If both are present in a Spring Boot project, both files can be loaded, but the active configuration source will depend on which format is used to define a particular setting.
- How to externalize configuration in Spring Boot?
To externalize configuration in Spring Boot, you can use the following methods:
- application.properties or application.yml: Store configuration in these files, which are automatically loaded by Spring Boot.
- Environment Variables: Map properties to environment variables using the format SPRING_<PROPERTY_NAME>, like SPRING_DATASOURCE_URL.
- Command-Line Arguments: Pass properties when starting the app (e.g., java -jar app.jar –server.port=8081), which override other configuration sources.
- Profiles: Use Spring profiles (application-dev.properties, application-prod.properties) for environment-specific configurations, activated by SPRING_PROFILES_ACTIVE.
- Config Server (for microservices): In distributed systems, Spring Cloud Config Server centralizes configuration management.
- Config Data API (from Spring Boot 2.4): A flexible API for loading configuration from external sources like files or databases.
- What is @Value used for?
Answer: The @Value annotation is used to inject property values into Spring beans.
Example:
@Value("${company.maxEmployees}")
private int maxEmployees;
- What are Spring Profiles and how do they work?
Answer: Spring Profiles are used to define different configurations for different environments (dev, prod, test, etc.).
Example: spring.profiles.active=dev
Spring Boot RESTful Web Services
- What is @RestController in Spring Boot?
Answer: @RestController is used to define RESTful APIs. It combines @Controller and @ResponseBody, meaning it returns data (JSON, XML) instead of views.
Example:
@RestController
@RequestMapping("/api")
public class MyController {
@GetMapping("/greet")
public String greet() {
return "Hello, World!";
}
}
- How to create a simple RESTful API using Spring Boot?
Answer: Create a @RestController with appropriate mappings (@GetMapping, @PostMapping, etc.).
Example:
@RestController
public class UserController {
@GetMapping("/users")
public List<User> getAllUsers() {
return userService.getAllUsers();
}
}
- How to handle HTTP request methods like GET, POST, PUT, DELETE in Spring Boot?
Answer: Use @GetMapping, @PostMapping, @PutMapping, @DeleteMapping to map HTTP methods to handler methods.
Example:
@PostMapping("/users")
public User createUser(@RequestBody User user) {
return userService.createUser(user);
}
- What is the use of @RequestBody and @ResponseBody annotations?
Answer: @RequestBody binds the HTTP request body to a method parameter, and @ResponseBody tells Spring to bind the return value to the HTTP response body.
- How do you handle query parameters in Spring Boot?
Answer: Use @RequestParam to bind query parameters to method arguments.
Example:
@GetMapping("/users")
public List<User> getUsers(@RequestParam("name") String name) {
return userService.getUsersByName(name);
}
Data Access with Spring Boot
- How to connect Spring Boot with a database?
Answer: Use spring-boot-starter-data-jpa along with a JPA provider like Hibernate.
Example:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
- How can you configure and use multiple databases in a Spring Boot application?
To use multiple databases in Spring Boot, you need to configure multiple data sources and create separate DataSource, EntityManagerFactory, and TransactionManager beans for each database. Here’s how you can do it:
Configure application.properties or application.yml:
Define the connection properties for each database.
# Primary Database Configuration
spring.datasource.primary.url=jdbc:mysql://localhost:3306/db1
spring.datasource.primary.username=root
spring.datasource.primary.password=root
spring.datasource.primary.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.primary.jpa.hibernate.ddl-auto=update
spring.datasource.primary.jpa.show-sql=true
# Secondary Database Configuration
spring.datasource.secondary.url=jdbc:mysql://localhost:3306/db2
spring.datasource.secondary.username=root
spring.datasource.secondary.password=root
spring.datasource.secondary.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.secondary.jpa.hibernate.ddl-auto=update
spring.datasource.secondary.jpa.show-sql=true
Create DataSource Configurations:
You will need to create a configuration class to define separate DataSource, EntityManagerFactory, and TransactionManager for each database.
@Configuration
@EnableTransactionManagement
public class DataSourceConfig {
@Primary
@Bean(name = "primaryDataSource")
@ConfigurationProperties(prefix = "spring.datasource.primary")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "secondaryDataSource")
@ConfigurationProperties(prefix = "spring.datasource.secondary")
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean(name = "primaryEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(
EntityManagerFactoryBuilder builder,
@Qualifier("primaryDataSource") DataSource dataSource) {
return builder
.dataSource(dataSource)
.packages("com.example.model.primary") // package containing primary DB entities
.persistenceUnit("primary")
.build();
}
@Bean(name = "secondaryEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean secondaryEntityManagerFactory(
EntityManagerFactoryBuilder builder,
@Qualifier("secondaryDataSource") DataSource dataSource) {
return builder
.dataSource(dataSource)
.packages("com.example.model.secondary") // package containing secondary DB entities
.persistenceUnit("secondary")
.build();
}
@Primary
@Bean(name = "primaryTransactionManager")
public PlatformTransactionManager primaryTransactionManager(
@Qualifier("primaryEntityManagerFactory") EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
@Bean(name = "secondaryTransactionManager")
public PlatformTransactionManager secondaryTransactionManager(
@Qualifier("secondaryEntityManagerFactory") EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
}
Define Repositories:
Create repository interfaces for each database, using the @EnableJpaRepositories annotation to specify the entityManagerFactory and transactionManager for each database.
@Configuration
@EnableJpaRepositories(
basePackages = "com.example.repository.primary",
entityManagerFactoryRef = "primaryEntityManagerFactory",
transactionManagerRef = "primaryTransactionManager"
)
public class PrimaryDatabaseConfig {}
@Configuration
@EnableJpaRepositories(
basePackages = "com.example.repository.secondary",
entityManagerFactoryRef = "secondaryEntityManagerFactory",
transactionManagerRef = "secondaryTransactionManager"
)
public class SecondaryDatabaseConfig {}
- What is Spring Data JPA?
Answer: Spring Data JPA is part of the Spring Data project that simplifies database interactions by providing a repository-based approach. It reduces boilerplate code for CRUD operations, query creation, and pagination by automatically implementing repository interfaces like JpaRepository. You can also define custom queries with the @Query annotation. Spring Data JPA integrates seamlessly with JPA and supports powerful features like query derivation, sorting, and pagination, making database access easier and more efficient.
- What is @Entity annotation?
Answer: @Entity marks a class as a JPA entity, which will be mapped to a table in the database.
Example:
@Entity
public class User {
@Id
private Long id;
private String name;
}
- What is @Repository annotation in Spring Boot?
Answer: The @Repository annotation in Spring Boot is a specialization of the @Component annotation that marks a class as a Data Access Object (DAO). It is typically used for classes that interact with databases, managing the data access logic.
When a class is annotated with @Repository, Spring automatically handles the class as a Spring bean, making it eligible for component scanning. Additionally, @Repository provides automatic exception translation, converting database-related exceptions (like SQLException) into Spring’s DataAccessException, allowing for more consistent error handling across different types of databases.
- Explain the @Transactional annotation in Spring Boot.
Answer: @Transactional ensures that a method or class runs within a transaction, making sure that all operations are either committed or rolled back together.
Example:
@Transactional
public void transferMoney(Account from, Account to, double amount) {
from.withdraw(amount);
to.deposit(amount);
}
Spring Boot Security
- How many ways can we implement security in Spring Boot?
There are several ways to implement security in a Spring Boot application. The primary methods include:
- Spring Security:
- Spring Security is the most common and comprehensive way to implement security in Spring Boot. It provides authentication, authorization, and various other security features like CSRF protection, HTTP Basic authentication, OAuth2, and more.
- You can configure it using either Java configuration (@EnableWebSecurity and WebSecurityConfigurerAdapter) or by using custom filters and handlers.
- Basic Authentication:
- Basic authentication is a simple method where the client sends a username and password with each HTTP request.
- Spring Security can be configured to use HTTP Basic authentication with simple configurations in application.properties or through Java config.
- JWT (JSON Web Token) Authentication:
- JWT is commonly used in stateless applications. Spring Boot can be integrated with JWT for token-based authentication, where the client receives a token after logging in and uses it for subsequent requests.
- This is typically used in RESTful APIs for secure user authentication.
- OAuth2 and OpenID Connect:
- OAuth2 is used for secure delegated access, and Spring Boot provides easy integration with OAuth2 providers like Google, Facebook, or custom OAuth2 services.
- OpenID Connect (an identity layer on top of OAuth2) is also commonly used for Single Sign-On (SSO) and can be integrated using Spring Security OAuth2 login.
- LDAP Authentication:
- Spring Boot supports LDAP (Lightweight Directory Access Protocol) for authentication against directory services like Active Directory or other LDAP servers.
- You can configure Spring Security to integrate with LDAP for user authentication.
- Form-Based Authentication:
- This is a traditional approach where Spring Security is configured to use a custom login page with username and password fields.
- You can also use Spring Security’s default login page, or customize it as needed.
- Method-Level Security (Pre/Post Authorization):
- You can use annotations like @PreAuthorize and @Secured on methods to enforce access control at the service layer, restricting method execution based on user roles or permissions.
- How to configure Spring Security in Spring Boot?
Answer: Use spring-boot-starter-security to configure authentication and authorization.
Example:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
- What is @EnableWebSecurity annotation?
Answer: @EnableWebSecurity is an annotation in Spring Security that enables web security support in a Spring application. It triggers the configuration of Spring Security’s default web security mechanisms, allowing you to customize security settings for your web application, such as authentication, authorization, and CSRF protection.
- How do you handle authentication and authorization in Spring Boot?
Answer:
In Spring Boot, authentication can be handled using methods like username/password authentication, JWT tokens, OAuth, or LDAP. You can configure Spring Security to authenticate users based on different mechanisms, such as form-based login, basic authentication, or token-based authentication like JWT.
For authorization, you control access to resources using roles or permissions. Spring Security allows you to configure role-based access control (RBAC) using annotations like @PreAuthorize or @Secured, or by configuring HTTP security rules to restrict access to certain URLs based on the user’s roles or authorities.
- What is Basic Authentication in Spring Boot?
Answer: Basic Authentication requires a username and password with every request.
Example:
@Override
protected void configure(HttpSecurity http) throws Exception {
http.httpBasic().and().authorizeRequests().anyRequest().authenticated();
}
- How to configure form-based login in Spring Boot?
Answer: You can configure form-based login by using formLogin() method in your security configuration.
Example: http.formLogin().loginPage(“/login”).permitAll();
Spring Boot Testing
- What is @SpringBootTest used for?
Answer: @SpringBootTest is used to run an entire Spring Boot application context for integration tests.
- How do you test a REST controller in Spring Boot?
Answer: You can use @WebMvcTest for unit testing REST controllers and @SpringBootTest for full application integration tests.
- What is @MockBean used for in Spring Boot?
Answer: @MockBean is used to create mock beans in your application context for testing purposes.
- How to test service layers in Spring Boot?
Answer: Service layers can be tested using @MockBean to mock repositories and other dependencies.
Example:
@MockBean
private UserRepository userRepository;
- How do you handle exceptions in Spring Boot?
Answer: You can handle exceptions globally using @ControllerAdvice or locally using @ExceptionHandler.
Example:
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ResponseEntity<String> handleException(Exception ex) {
return new ResponseEntity<>(ex.getMessage(), HttpStatus.INTERNAL_SERVER_ERROR);
}
}
Advanced Spring Boot Topics
- What is Spring Boot Actuator?
Answer: Spring Boot Actuator provides production-ready features such as Health Checks, Metrics, Application Info, Auditing, Environment Properties, Logging, Thread Dumps, Shutdown, Cache, Custom Endpoints.
- How to create a custom Spring Boot Starter?
To create a custom Spring Boot Starter, follow these steps:
- Create a new project:
Set up a new Maven or Gradle project.
- Define Auto-Configuration:
Create a configuration class with the @Configuration annotation. Use @EnableAutoConfiguration or @AutoConfigureBefore/@AutoConfigureAfter to specify when the auto-configuration should take place.
- Add spring.factories file:
Inside src/main/resources/META-INF, create a spring.factories file. This file should point to your auto-configuration class.
Example:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.MyCustomAutoConfiguration
- Package it into a JAR:
Package your project as a JAR file, which can be included as a dependency in other Spring Boot projects.
- Use the starter:
In the dependent Spring Boot project, include the custom starter as a dependency.
- What is Spring Boot DevTools?
Answer: Spring Boot DevTools provides features to enhance development productivity, including automatic restart for faster feedback during development, live reload for updating the application in the browser automatically, and enhanced logging to help with debugging and tracing application behavior more effectively.
- How to configure Spring Boot to use a custom port?
Answer: You can configure the server port using server.port in application.properties or using yaml.
Example: server.port=8081
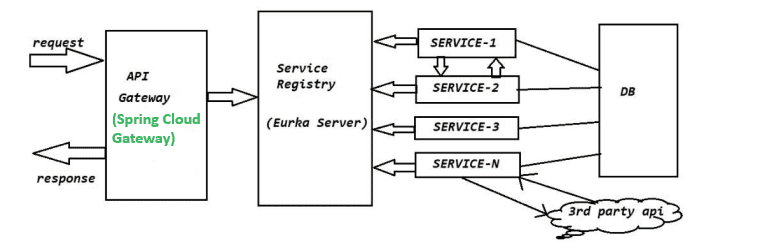
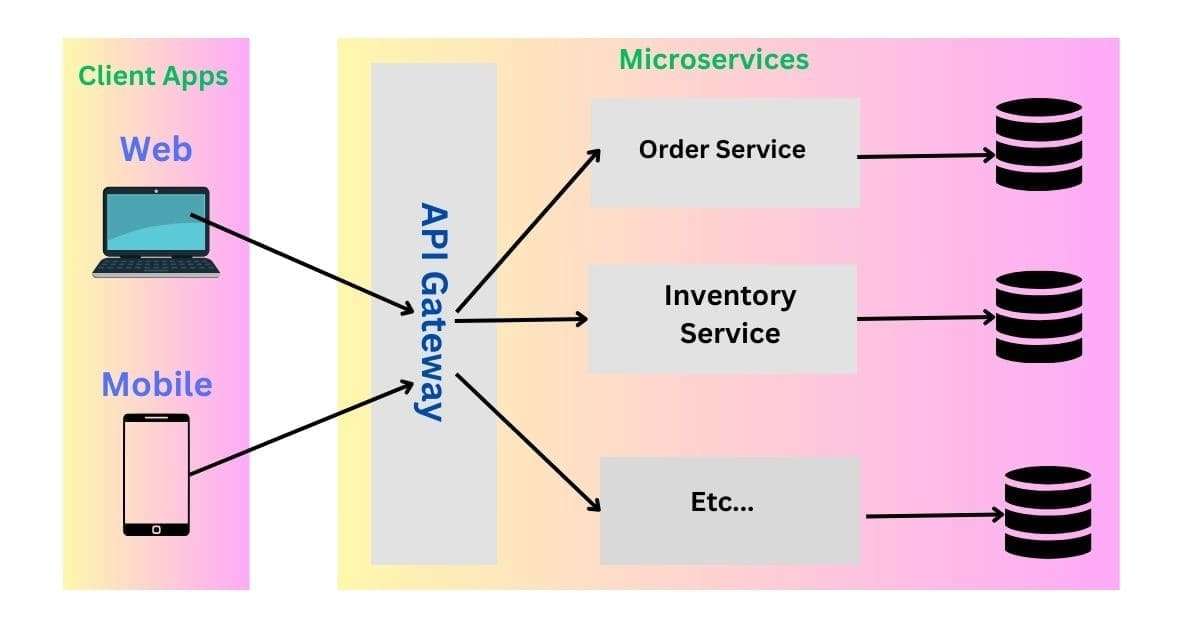
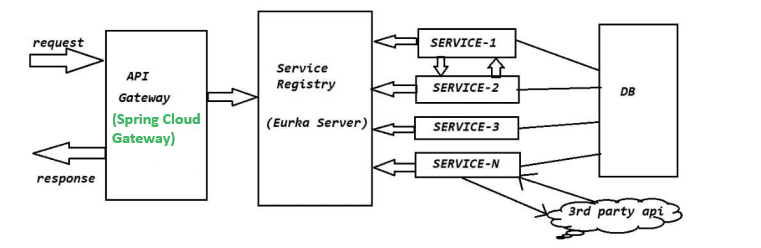
- What is Spring Boot’s support for microservices?
Answer: Spring Boot integrates seamlessly with Spring Cloud to support the development of microservices. It provides essential features such as service discovery (via Eureka), an API gateway (using Spring Cloud Gateway or Zuul), centralized configuration management (using Spring Cloud Config), circuit breakers (via Hystrix or Resilience4J), and distributed tracing. These features enable the creation, deployment, and management of scalable, resilient microservice architectures.
Spring Boot and Cloud
- What is Spring Cloud and how does it integrate with Spring Boot?
Answer: Spring Cloud provides tools for microservice architecture, such as service discovery (Eureka), circuit breakers (Hystrix), and configuration management (Config Server).
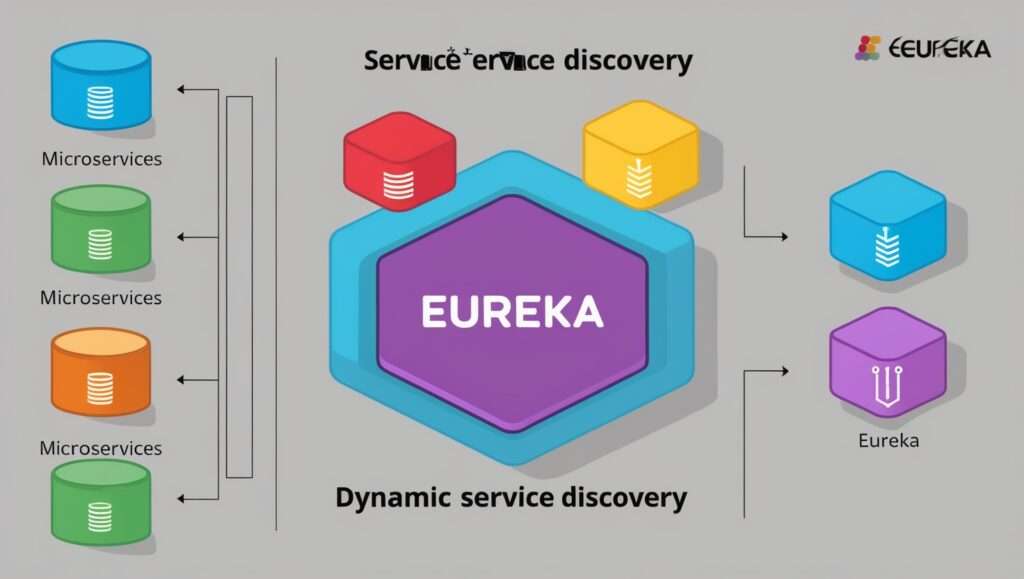
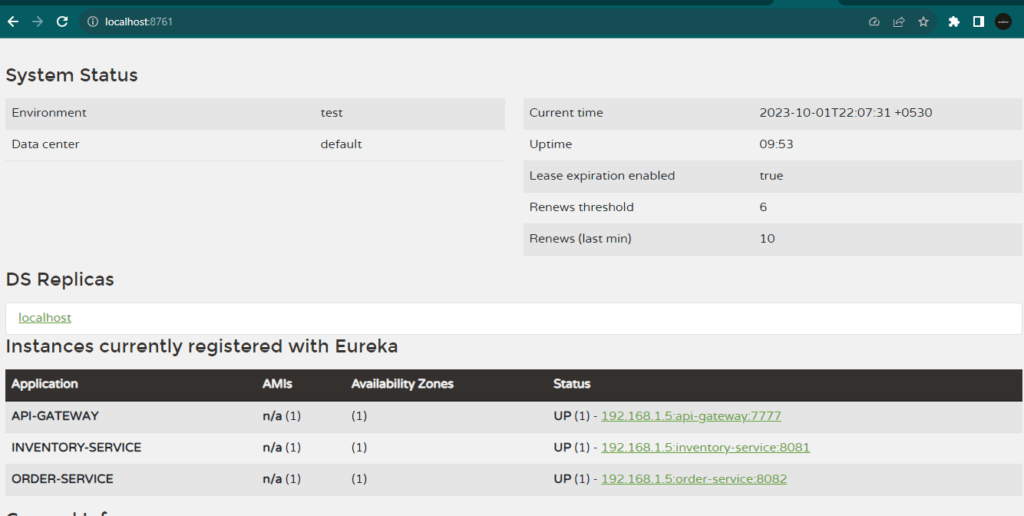
- How to use Spring Boot with Eureka for service discovery?
Answer: Add the spring-cloud-starter-netflix-eureka-client dependency and enable service discovery with @EnableDiscoveryClient.
- What is Spring Cloud Config?
Answer: Spring Cloud Config is a framework used to manage external configurations for applications in a distributed system. It provides a central server that stores configuration data, allowing multiple microservices to retrieve and refresh their configuration at runtime. This enables consistent and centralized management of configuration across various environments and services, improving flexibility and maintainability in cloud-native applications.
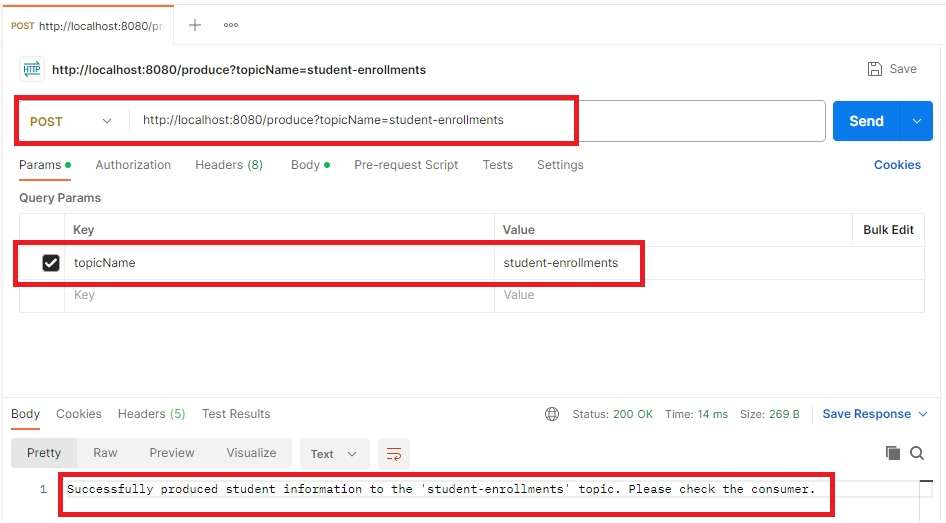
- How to integrate Spring Boot with Kafka?
Answer: Use spring-kafka starter to integrate Kafka for messaging.
Example:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- How does Spring Boot support Docker?
Answer: Spring Boot supports Docker by allowing applications to be packaged as Docker containers. You can create a Dockerfile to define how to build the Docker image, typically by adding the Spring Boot JAR file and specifying the entry point to run the application. Additionally, the spring-boot-maven-plugin simplifies the process by allowing you to build Docker images as part of the Maven build lifecycle. This makes it easy to deploy Spring Boot applications in Docker environments for consistent, isolated deployments.
Miscellaneous
- How to schedule tasks in Spring Boot?
Answer: You can schedule tasks using @EnableScheduling and @Scheduled annotations.
- What is Spring Boot’s default logging framework?
Answer: Spring Boot uses Logback as the default logging framework. Logback is a powerful, flexible, and fast logging library, and Spring Boot configures it automatically. It supports different logging levels (e.g., INFO, DEBUG, ERROR) and allows for easy configuration via application.properties or application.yml files. Spring Boot also provides integration with other logging frameworks, such as Log4j2, if needed.
- How do you enable SSL in Spring Boot?
Answer: SSL can be enabled in Spring Boot by configuring the server.ssl properties in the application.properties or application.yml file. You need to specify the location of the SSL key store, the password, and other related properties. Here’s an example configuration in
application.properties:
server.port=8443
server.ssl.key-store=classpath:keystore.jks
server.ssl.key-store-password=your-password
server.ssl.key-store-type=JKS
server.ssl.key-alias=your-alias
- What is the role of @ComponentScan in Spring Boot?
Answer: @ComponentScan is used in Spring Boot to specify the packages that Spring should scan for annotated components, such as @Controller, @Service, @Repository, and @Component. It tells Spring where to find the beans and automatically register them in the application context. By default, @SpringBootApplication includes @ComponentScan, which scans the current package and its sub-packages for components. However, you can customize the scan path by specifying base packages in @ComponentScan if needed.
- How to handle asynchronous processing in Spring Boot?
Answer: In Spring Boot, asynchronous processing can be handled using the @Async annotation, which allows methods to run asynchronously in a separate thread. To enable asynchronous processing, you need to add the @EnableAsync annotation to a configuration class.
Here’s how we can implement it:
- Enable Async Processing: In your configuration class, add @EnableAsync to enable async processing:
@Configuration
@EnableAsync
public class AsyncConfig {
}
Mark Method as Async: Use the @Async annotation on methods that should run asynchronously:
@Service
public class MyService {
@Async
public CompletableFuture<String> processTask() {
// Simulate a long-running task
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return CompletableFuture.completedFuture("Task completed");
}
}
When the method marked with @Async is called, it will run in a separate thread, allowing the main thread to continue without waiting for the method to complete.
Spring Boot Security
- What is Spring Security?
Answer: Spring Security is a powerful and customizable authentication and access control framework for Java applications. It provides comprehensive security services such as authentication, authorization, and protection against common vulnerabilities.
- How do you enable Spring Security in a Spring Boot application?
Answer: You can enable Spring Security by adding spring-boot-starter-security to the pom.xml file.
Example:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
- What is the default username and password when Spring Security is enabled?
Answer: The default username is user and the password is generated at startup and logged to the console.
- How to configure custom login page in Spring Security?
Answer: You can configure a custom login page using formLogin() in the configure(HttpSecurity http) method of WebSecurityConfigurerAdapter.
Example:
@Override
protected void configure(HttpSecurity http) throws Exception {
http.formLogin().loginPage("/login").permitAll();
}
- What is method-level security in Spring Security?
Answer: Method-level security allows you to apply security rules at the method level, such as restricting access to certain methods based on roles or permissions.
Example:
@PreAuthorize("hasRole('ADMIN')")
public void someMethod() {
// Method implementation
}
- What is JWT (JSON Web Token) and how does it work with Spring Boot?
Answer: JWT is a compact, URL-safe means of representing claims to be transferred between two parties. It is often used for stateless authentication in REST APIs.
Example:
- After successful login, a JWT token is generated and sent back to the client.
- The client includes the token in the Authorization header for subsequent requests.
- How to implement basic authentication in Spring Boot?
Answer: Basic authentication can be implemented by configuring HTTP security with httpBasic() in your security configuration class.
Example:
@Override
protected void configure(HttpSecurity http) throws Exception {
http.httpBasic().and().authorizeRequests().anyRequest().authenticated();
}
- What is CSRF (Cross-Site Request Forgery) protection in Spring Security?
Answer: CSRF is a security vulnerability that allows attackers to perform unwanted actions on behalf of a user. Spring Security provides CSRF protection by default. You can disable it if necessary, but it’s not recommended for production.
Example: http.csrf().disable(); // Disables CSRF protection (not recommended in production)
- What is Spring Security OAuth2?
Answer: Spring Security OAuth2 is an implementation of OAuth2 (an open standard for access delegation) that enables secure authorization and authentication for applications.
- How can you integrate Spring Boot with LDAP for authentication?
Answer: Use the spring-boot-starter-ldap to authenticate users against an LDAP directory.
Example:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-ldap</artifactId>
</dependency>
Messaging in Spring Boot
- What is Spring Boot’s support for messaging?
Answer: Spring Boot supports messaging using JMS, AMQP (Advanced Message Queuing Protocol), and other messaging systems like Kafka and RabbitMQ.
- How to configure a message broker in Spring Boot?
Answer: You can configure a message broker, such as RabbitMQ or Kafka, by adding the necessary starter dependencies and application properties.
Example for RabbitMQ:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- How do you send and receive messages with RabbitMQ in Spring Boot?
Answer: Use @RabbitListener for consuming messages and RabbitTemplate for sending messages.
Example:
@RabbitListener(queues = "queueName")
public void receiveMessage(String message) {
System.out.println("Received: " + message);
}
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage(String message) {
rabbitTemplate.convertAndSend("queueName", message);
}
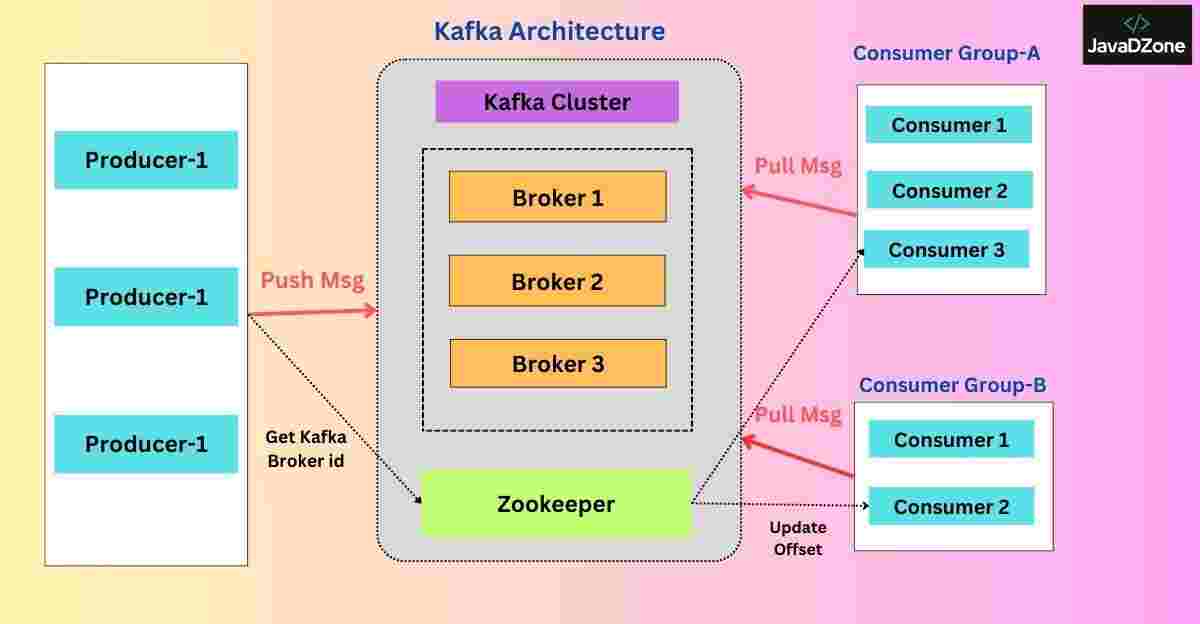
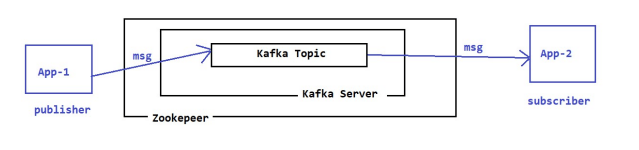
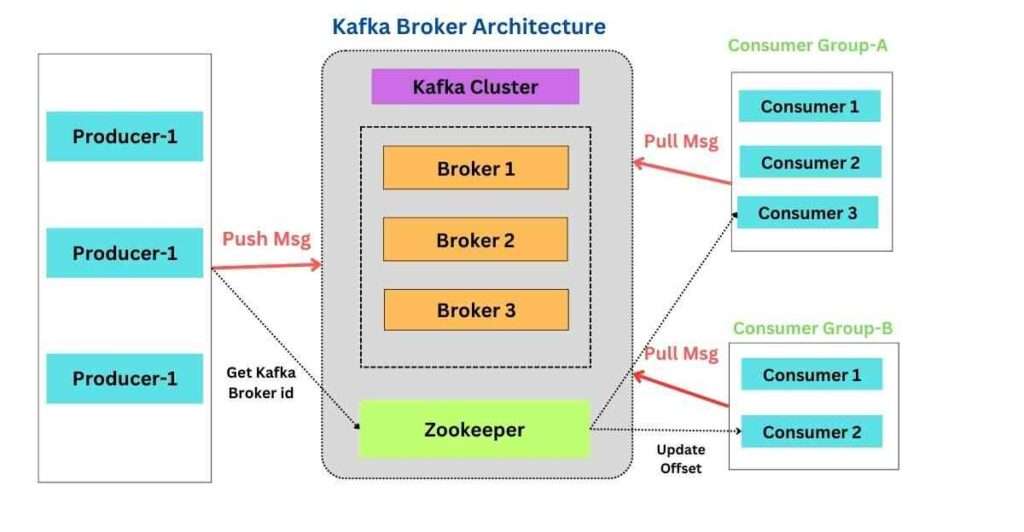
- What is Spring Kafka and how is it used in Spring Boot?
Answer: Spring Kafka is a Spring framework project that provides seamless integration with Apache Kafka, an open-source distributed streaming platform. Apache Kafka is widely used for building real-time data pipelines and streaming applications due to its ability to handle high throughput and distributed data. Spring Kafka helps developers easily interact with Kafka for messaging, event-driven architectures, and data processing in Spring-based applications.
Spring Kafka integrates Kafka’s producer-consumer model into Spring Boot, simplifying the configuration and usage of Kafka in your applications. It provides abstractions for both producing messages to Kafka topics and consuming messages from Kafka topics.
Example:
<dependency>
<groupId>org.springframework.kafka</groupId>
artifactId>spring-kafka</artifactId>
</dependency>
- How do you configure a Kafka producer and consumer in Spring Boot?
Answer: Configure Kafka properties in application.properties and define Kafka producer and consumer beans.
Example:
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=test-group
Reactive Programming with Spring Boot
- What is Reactive Programming in Spring Boot?
Answer: Reactive Programming is a paradigm that allows handling asynchronous data streams and events. In Spring Boot, it is supported by Spring WebFlux, which allows you to create non-blocking applications.
- What is Spring WebFlux?
Answer: Spring WebFlux is a reactive-stack web framework in Spring, introduced as an alternative to Spring MVC for handling asynchronous processing and backpressure.
- What are Mono and Flux in Spring WebFlux?
Answer: Mono represents a single asynchronous value or empty value, while Flux represents a stream of multiple values.
Example:
Mono<String> helloMono = Mono.just("Hello");
Flux<String> helloFlux = Flux.just("Hello", "World");
- How to use @GetMapping in Spring WebFlux?
Answer: In WebFlux, you can use @GetMapping in a reactive controller to return Mono or Flux as the response body.
Example:
@RestController
public class WebFluxController {
@GetMapping("/mono")
public Mono<String> getMono() {
return Mono.just("Hello, Reactive World!");
}
}
- How do you handle exceptions in WebFlux?
Answer: You can use @ExceptionHandler to handle exceptions in WebFlux controllers, or implement a global exception handler using @ControllerAdvice.
- What is a @ResponseStatus in WebFlux?
- Answer: @ResponseStatus is used to mark an exception or a method to return a specific HTTP status code.
Spring Boot with Cloud
- What is Spring Cloud?
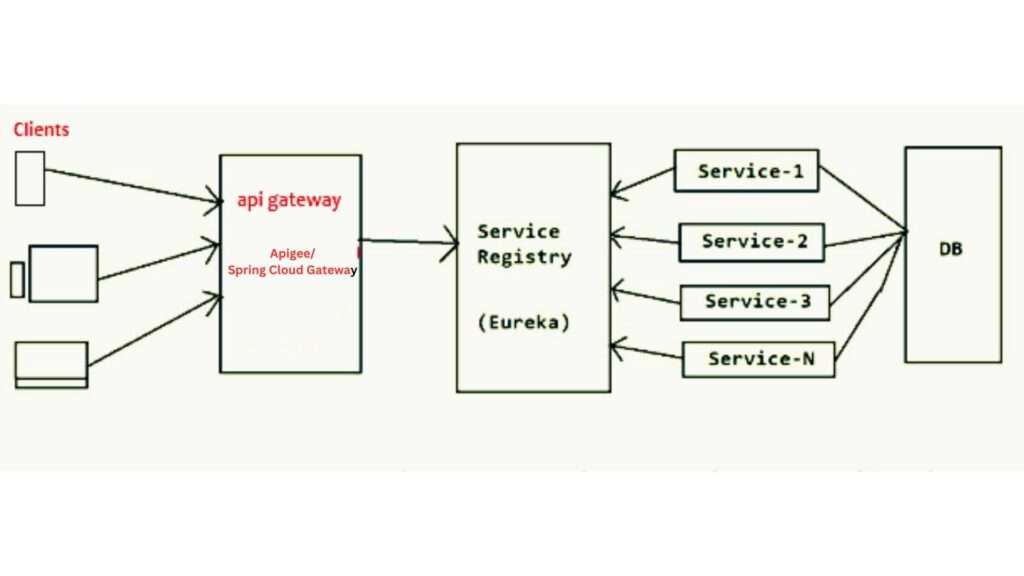
Answer: Spring Cloud is a collection of tools and frameworks designed to help developers build distributed systems and microservices architectures. It provides a range of solutions for common challenges in microservices, such as:
- Service Discovery (e.g., Eureka)
- Centralized Configuration Management (e.g., Spring Cloud Config)
- API Gateway (e.g., Spring Cloud Gateway)
- Load Balancing (e.g., Ribbon)
- Circuit Breakers (e.g., Hystrix)
- Messaging (e.g., Kafka, RabbitMQ)
Spring Cloud integrates seamlessly with Spring Boot to help you develop scalable, resilient, and easily manageable microservices applications.
- How do you use Spring Cloud Eureka for service discovery?
Answer: Spring Cloud Eureka is used for service registration and discovery. You need to add the spring-cloud-starter-netflix-eureka-client dependency and enable discovery with @EnableDiscoveryClient.
Example:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- What is Spring Cloud Config?
Answer: Spring Cloud Config is a framework used for centralized configuration management in distributed systems. It allows you to store and manage configuration properties for multiple microservices in one central place, making it easier to maintain and update configurations across different environments (e.g., development, staging, production).
Spring Cloud Config can be used to access configurations from various sources like Git repositories, local files, or a database.
Example:
spring.cloud.config.uri=http://config-server:8888
- How do you configure Spring Boot with Spring Cloud Config Server?
Answer: Set up a @EnableConfigServer on a Spring Boot application to act as the Config Server, and point applications to it for configuration management.
Example:
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}
- What is Spring Cloud Gateway and how is it used with Spring Boot?
Answer: Spring Cloud Gateway is used to route requests to different services in a microservices architecture, acting as an API gateway.
Example:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
- How do you implement load balancing in Spring Boot with Spring Cloud?
Answer: Spring Cloud integrates with Ribbon (client-side load balancing) to distribute requests among different service instances. Use @LoadBalanced annotation with RestTemplate to enable load balancing.
Example:
@LoadBalanced
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
- What is Spring Cloud Circuit Breaker and how is it used?
Answer: Spring Cloud Circuit Breaker (commonly using Hystrix or Resilience4J) helps manage failures in a microservice-based system by preventing cascading failures.
Example:
@HystrixCommand(fallbackMethod = "fallback")
public String callService() {
return restTemplate.getForObject("http://myservice", String.class);
}
public String fallback() {
return "Service is down";
}
- How does Spring Boot work with Docker in the cloud?
Answer: Spring Boot applications can be easily packaged into Docker containers for cloud deployment, allowing them to run in isolated environments. This process involves creating a Dockerfile to define how the application should be built and run inside a Docker container. You can build the Docker image using build tools like Maven or Gradle.
Spring Boot Miscellaneous Topics
- What are Spring Boot Profiles?
Answer: Spring Boot Profiles allow you to define and manage different configurations for different environments, such as development (dev), testing (test), and production (prod). Profiles enable you to have environment-specific settings without changing the main application code.
You can specify which profile is active by setting the spring.profiles.active property in your application.properties or application.yml file, or by passing it as a command-line argument.
Example:
- Define multiple profiles in application.properties:
For development environment:
# application-dev.properties
server.port=8081
datasource.url=jdbc:mysql://localhost:3306/dev_db
For production environment:
# application-prod.properties
server.port=8080
datasource.url=jdbc:mysql://prod-db-server:3306/prod_db
- Activate a profile:
In the application.properties file, you can specify the active profile:
spring.profiles.active=dev
Spring Boot will load the appropriate configuration based on the active profile, allowing you to easily switch between different environments. This makes it simple to manage settings like database URLs, logging levels, and server ports based on the environment.
- How to monitor Spring Boot applications?
Answer: You can monitor Spring Boot applications using Spring Boot Actuator, which provides a set of production-ready features such as health checks, metrics, and application environment details. By integrating Spring Boot Actuator with monitoring systems like Prometheus, Grafana, or Micrometer, you can get real-time monitoring and insights into the application’s performance, health, and resource usage.
- How to use Spring Boot with external services like Redis or MongoDB?
Answer: Use the relevant Spring Boot starters (spring-boot-starter-data-redis, spring-boot-starter-data-mongodb) and configure the connection properties in application.properties.
- How do you package a Spring Boot application as a WAR?
Answer: To package a Spring Boot application as a WAR (Web Application Archive) for deployment to a traditional servlet container (e.g., Tomcat, Jetty), follow these steps:
- Change the packaging type to WAR: In your pom.xml, change the packaging type from jar to war: <packaging>war</packaging>
- Extend SpringBootServletInitializer: To configure the application to work as a WAR file in a servlet container, extend the SpringBootServletInitializer class in your main application class.
Example:
@SpringBootApplication
public class MyApplication extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder application) {
return application.sources(MyApplication.class);
}
}
- Add a web.xml file (optional): If your application needs a custom configuration for a servlet container, you can add a web.xml file, but this is typically optional in Spring Boot.
Once you’ve made these changes, you can build the WAR file using Maven or Gradle:
The resulting .war file can be deployed to a servlet container like Apache Tomcat. This approach allows you to run the Spring Boot application on an external server, while still leveraging Spring Boot’s configuration and other features.
Conclusion
Congratulations on completing the Spring Boot Interview Preparation Guide!
In this guide, we’ve explored everything from the basics of Spring Boot to advanced topics such as security, messaging, reactive programming, and cloud integration. With this knowledge, you’re now well-equipped to tackle Spring Boot-related interview questions with confidence.
Key Interview Preparation Tips:
- Practice coding regularly and solve Spring Boot-specific coding challenges.
- Gain hands-on experience by building real-world applications using Spring Boot.
- Focus on understanding core concepts and how they apply in different scenarios.
I encourage you to stay curious and continue exploring Spring Boot beyond this guide. Real mastery comes with continuous learning and real-world application.
Stay Connected and Join the Community:
To continue your learning journey and stay updated with the latest Spring Boot trends, tutorials, and discussions, join our WhatsApp channel: Click here to join
By joining, you’ll be part of a community where you can ask questions, share insights, and stay updated on new resources that will help you excel in Spring Boot.
Good luck with your interviews, and happy coding!